最近被各种AI大模型刷屏了,不论是公众号还是短视频,从ChatGPT到Alpaca,从ChatGLM到Bloom,各种大模型层出不穷,给人感觉“再不上车就来不及了”。
然而要上车大模型可不简单,首先,得准备至少几百张炼丹卡,或者直接上超算,普通人看看预算就自觉放弃了。
但是,AI时代已经来临,时代从来不会抛弃那些跟不上时代的人,而是直接从他们身上碾压过去。因此,普通人也有必要学习一点AI知识。
网上很多铺天盖地地在很高的层次大讲特讲人工智能对产业和人类的影响,还有一堆卖课程的,看完后没有收获知识,但收获了焦虑。
以工程师的视角从零开始搭建并运行一个AI小模型,并把它完全运行起来以理解AI的工作原理,非常接地气。
AI模型是如何工作的
神经网络是AI的一种重要的计算模型,深度学习是通过神经网络实现特征学习和模式分析,大量用于图像识别等领域。
我们以最基础的手写数字识别为例,看看一个神经网络的AI模型是如何工作的。
MNIST(Modified National Institute of Stands and Technology)是一个开源的数据集,它包含了6万个手写的数字图像,每个图像都是28x28黑底白字:
.png)
有了这个开源的数据集,我们就可以训练一个识别手写数字的AI模型,这个练习堪称AI界的“Hello, world”。
要编写这个AI模型,我们需要使用一种称为卷积神经网络(CNN:Convolutional Neural Network)的神经网络结构,具体到代码层面,则需要使用PyTorch这样的训练框架。
PyTorch 是一个开源的机器学习框架,用于构建深度学习模型。底层用C++开发,外层用Python调用,非常方便易用。先确保机器安装了Python3,然后,安装PyTorch 2:
pip install torch torchvision torchaudio
如果本机有CUDA环境,也可以安装GPU版本,训练速度更快。
CUDA环境指的是由英伟达NVIDIA所推出的一种软硬体整合技术。使用者可利用NVIDIA的GPU进行图像处理之外的运算,亦是首次可以利用GPU作为C-编译器的开发环境。
编写模型
准备好环境后,我们开始编写模型。先让AI写一个用CNN识别MNIST数据集的PyTorch代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 定义卷积神经网络模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
self.fc1 = nn.Linear(64*5*5, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = nn.functional.relu(self.conv1(x))
x = nn.functional.max_pool2d(x, 2)
x = nn.functional.relu(self.conv2(x))
x = nn.functional.max_pool2d(x, 2)
x = x.view(-1, 64*5*5)
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return nn.functional.log_softmax(x, dim=1)
# 设置训练参数
batch_size = 64
learning_rate = 0.01
epochs = 10
# 加载MNIST数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
# 初始化模型和优化器
model = CNN()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 训练模型
model.train()
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, epochs, batch_idx+1, len(train_loader), loss.item()))
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for data, target in test_loader:
output = model(data)
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy on the test set: {:.2f}%'.format(100 * correct / total))
ChatGPT给打代码段,并且给出了解释:
这段代码首先定义了一个简单的卷积神经网络模型 CNN,包含两个卷积层和两个全连接层。然后,使用torchvision库加载MNIST数据集,并设置数据加载器。接下来,定义了训练参数,包括批量大小、学习率和训练周期数。然后,初始化模型和优化器
看不懂不要紧,可以接着问AI,它会告诉我们,这个神经网络定义了两个CNN卷积层和两个全连接层,总的来说就是,这个模型定义了2层卷积网络加2层全连接层,输入为1通道图片,经过卷积和池化后进入全连接层,最后输出10个分类结果,分别代表0~9这10个数字。
训练
接下来我们要使用MNIST数据集来训练这个模型。受益于PyTorch这个框架,我们连下载和读取数据集都省了,因为PyTorch已经集成了这个数据集,直接下载、加载、训练,一步到位。
数据集分两部分:
- 一个用于训练
- 一个用于测试训练效果
用PyTorch的datasets.MNIST()自动下载、解压并加载数据集(解压后约55M数据,仅第一次需要下载)。
然后,定义损失函数和优化器,用train()做训练,用test()测试训练效果,训练5次,运行结果如下:
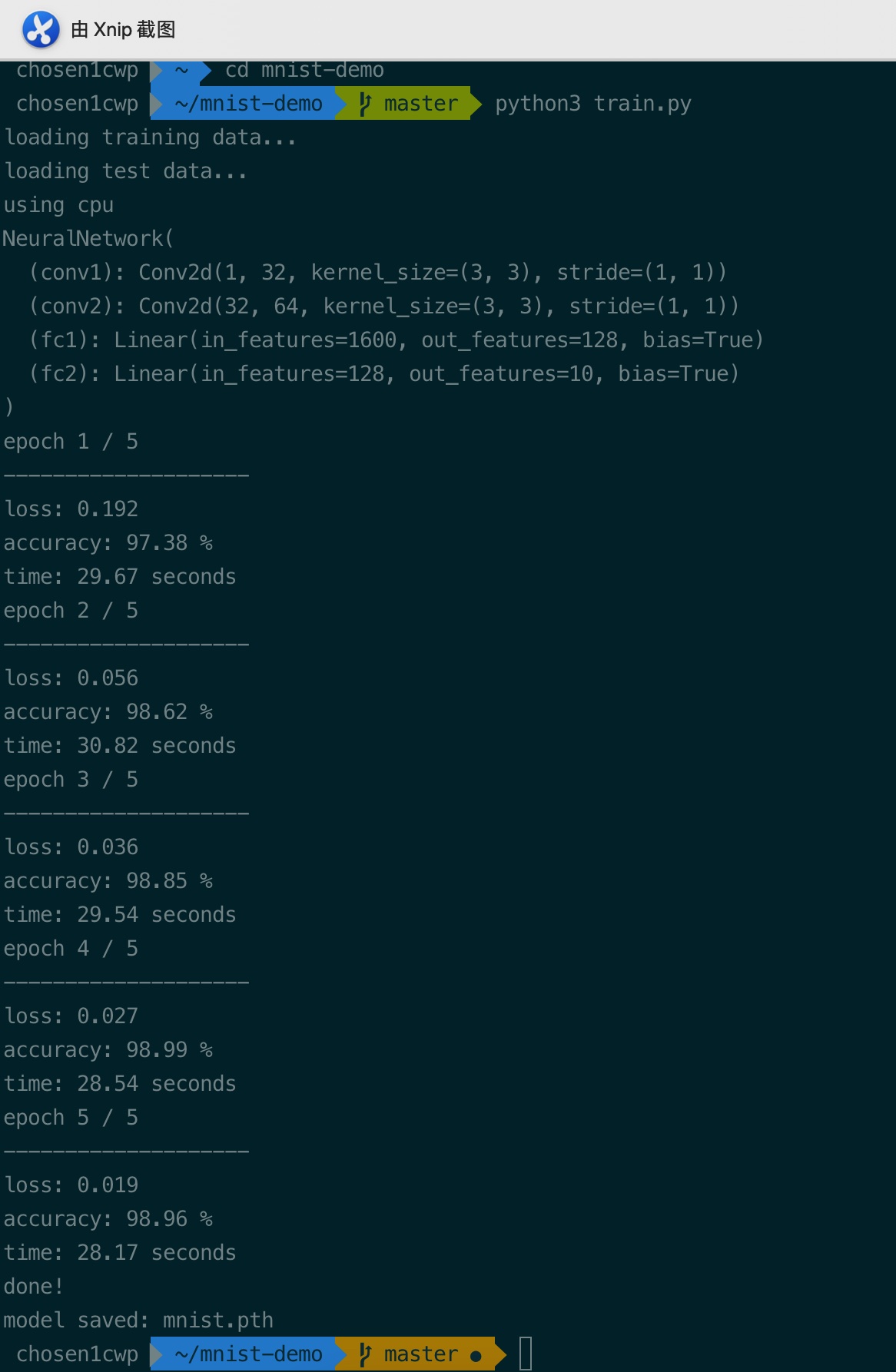
经过5轮训练,每轮耗时约30秒(这里用CPU训练,如果是GPU则可以大大提速),准确率可以达到99%。
训练结束后,将模型保存至mnist.pth文件。
使用模型
有了预训练的模型后,我们就可以用实际的手写图片测试一下。用PS手绘几张手写数字图片,测试代码如下:
import torch
from torchvision import transforms
from PIL import Image, ImageOps
from model import NeuralNetwork
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'using {device}')
model = NeuralNetwork().to(device)
path = './mnist.pth'
model.load_state_dict(torch.load(path))
print(f'loaded model from {path}')
print(model)
def test(path):
print(f'test {path}...')
image = Image.open(path).convert('RGB').resize((28, 28))
image = ImageOps.invert(image)
trans = transforms.Compose([
transforms.Grayscale(1),
transforms.ToTensor()
])
image_tensor = trans(image).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
output = model(image_tensor)
probs = torch.nn.functional.softmax(output[0], 0)
predict = torch.argmax(probs).item()
return predict, probs[predict], probs
def main():
for i in range(10):
predict, prob, probs = test(f'./input/test-{i}.png')
print(f'expected {i}, actual {predict}, {prob}, {probs}')
if __name__ == '__main__':
main()
因为训练时输入的图片是黑底白字,而测试图片是白底黑字,所以先用PIL把图片处理成28x28的黑底白字,再测试,结果如下:
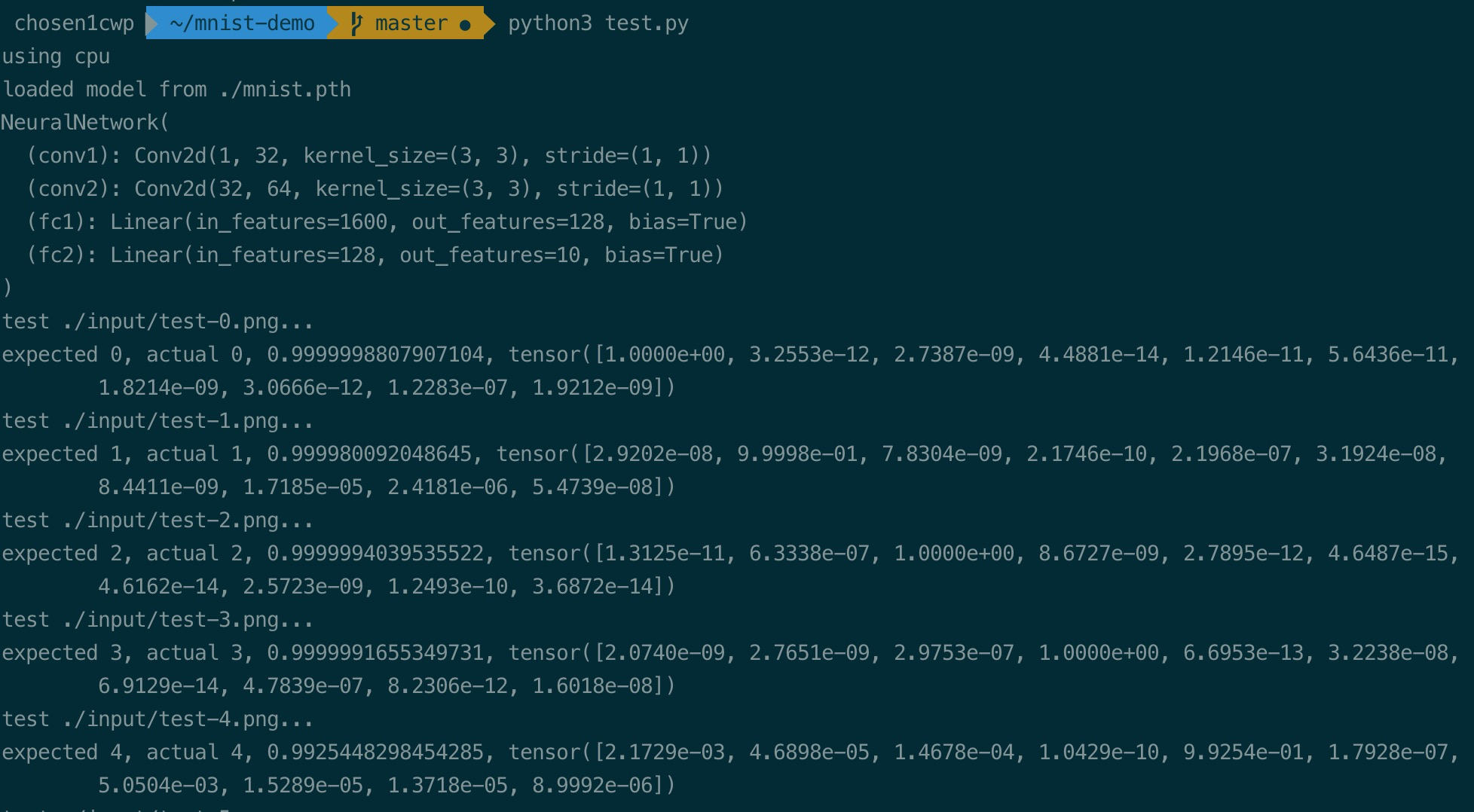
以图片0为例,我们要使用模型,需要把输入图片变成模型可接受的参数,实际上是一个Tensor(张量),可以理解为任意维度的数组,而模型的输出也是一个Tensor,它是一个包含10个元素的1维数组,分别表示每个输出的概率。
对图片0的输出如下:
- 1.0000e+00
- 2.3184e-10
- 1.7075e-08
- 7.6250e-16
- 1.2966e-12
- 5.7179e-11
- 2.1766e-07
- 1.8820e-12
- 1.1260e-07
- 2.2463e-09
除了第一个输出为1,其他输出都非常接近于0,可见模型以99.99996423721313%的概率认为图片是0,是其他数字的概率低到接近于0。
因此,这个MNIST模型实际上是一个图片分类器,或者说预测器,它针对任意图片输入,都会以概率形式给出10个预测,我们找出接近于1的输出,就是分类器给出的预测。
产品化
虽然我们已经有了预训练模型,也可以用模型进行手写数字识别,但是,要让用户能方便地使用这个模型,还需要进一步优化,至少需要提供一个UI。
我们让AI写一个简单的页面,允许用户在页面用鼠标手写数字,然后,通过API获得识别结果:
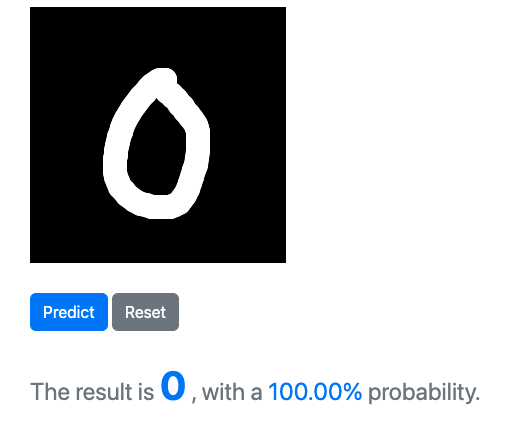
因此,最后一步是把模型的输入输出用API封装一下。
因为模型基于PyTorch,所以使用Python的Flask框架是最简单的。API实现如下:
import base64
import torch
from io import BytesIO
from PIL import Image
from flask import Flask, request, redirect, jsonify
from torchvision import transforms
from model import NeuralNetwork
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'using {device}')
model = NeuralNetwork().to(device)
path = './mnist.pth'
model.load_state_dict(torch.load(path))
print(f'loaded model from {path}')
print(model)
params = model.state_dict()
print(params)
app = Flask(__name__)
@app.route('/')
def index():
return redirect('/static/index.html')
@app.route('/api', methods=['POST'])
def api():
data = request.get_json()
image_data = base64.b64decode(data['image'])
image = Image.open(BytesIO(image_data))
trans = transforms.Compose([
transforms.Grayscale(1),
transforms.ToTensor()
])
image_tensor = trans(image).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
output = model(image_tensor)
probs = torch.nn.functional.softmax(output[0], 0)
predict = torch.argmax(probs).item()
prob = probs[predict]
print(f'predict: {predict}, prob: {prob}, probs: {probs}')
return jsonify({
'result': predict,
'probability': prob.item()
})
if __name__ == '__main__':
app.run(port=5000)
上述代码实现了一个简单的API服务,注意尚未对并发访问做处理,所以只能算一个可用的DEMO。
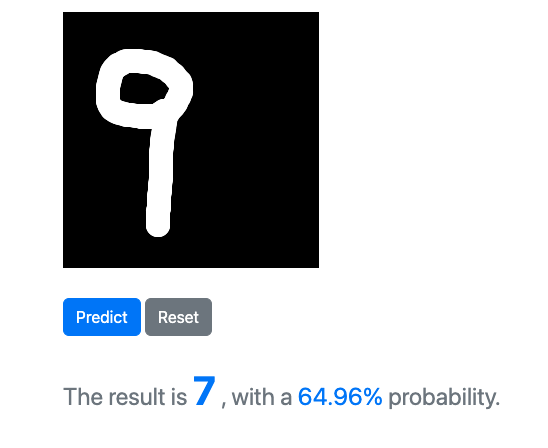
可是吧,准确性有待提升,比如:
思考
对于AI程序,我们发现,模型定义非常简单,一共也就20行代码。训练代码也很少,不超过100行。
AI程序和传统的程序最大的区别在哪呢?
相同点:
无论是传统的程序,还是AI程序,在计算机看来,本质上是一样的,即给定一个输入,通过一个函数计算,获得输出。
不同点:
对于传统程序,输入是非常简单的,例如用户注册,仅仅需要几个字段,而处理函数少则几千行,多则几十万行。虽然代码量很大,但执行路径却非常清晰,通过跟踪执行,能轻易获得一个确定的执行路径,从而最终获得一个确定性的结果。确定性就是传统程序的特点,或者说,传统程序的代码量虽然大,但输入简单,执行路径清晰
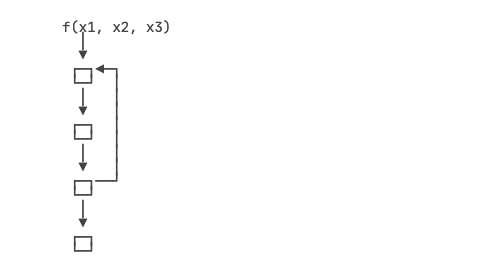
对于AI程序,它只经过几层计算,复杂的大模型也就100来层,就可以输出结果。但是,它的输入数据量大,每一层的数据量更大,就像一个扁平的巨大函数:
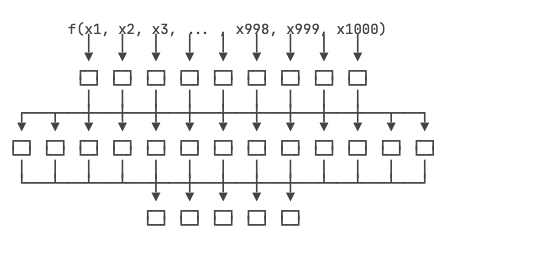
这个函数的计算并不复杂,每一层都是简单的矩阵计算,但并行程度很高,所以需要用GPU加速。复杂度在于每一层都有大量的参数,这些参数不是开发者写死的,而是通过训练确定的,每次对参数进行微调,然后根据效果是变得更好还是更坏决定微调方向。
我们这个简单的神经网络模型参数仅几万个,训练的目的实际上就是为了把这几万个参数确定下来,目标是使得识别率最高。
训练这几万个参数就花了几分钟时间,如果是几亿个甚至几百亿个参数,可想而知训练所需的时间和算力都需要百万倍的增长,所以,AI模型的代码并不复杂,模型规模大但本身结构并不复杂,但为了确定模型中每一层的成千上万个参数,时间和算力主要消耗在训练上。
传统程序与AI程序的比较
| - | 传统程序 | AI程序 |
|---|---|---|
| 代码量 | 大 | 小 |
| 输入参数 | 少 | 多 |
| 输出结果 | 精确输出 | 不确定性输出 |
| 代码参数 | 由开发设定 | 由训练决定 |
| 执行层次 | 可达数百万行 | 仅若干层网络 |
| 执行路径 | 能精确跟踪 | 无法跟踪 |
| 并行 | 串行或少量并行 | 大规模并行 |
| 计算 | 以CPU为主 | 以GPU为主 |
| 开发时间 | 主要消耗在编写代码 | 主要消耗在训练 |
| 数据 | 主要存储用户产生的数据 | 需要预备大量训练数据 |
| 程序质量 | 取决于设计架构、代码优化等 | 取决于神经网络模型和训练数据质量 |
传统程序的特点是精确性
精确的输入可以实现精确地执行路径,最终获得精确的结果。
而AI程序则是一种概率输出,由于模型的参数是训练生成的,因此,就连开发者自己也无法知道训练后的某个参数比如0.123究竟是什么意义,调大或者调小对输出有什么影响。
传统程序的逻辑是白盒,AI程序的逻辑就是黑盒,只能通过调整神经网络的规模、层次、训练集和训练方式来评估输出结果,无法事先给出一个准确的预估。